Defining what is possible and what is impossible is one of the main tasks that science solves every day. This is especially noticeable in the field of machine learning. Let’s take the recent Meta AI Galactica, a large language model trained on 48 mln. scientific papers. Until recently, if you visited https://galactica.org, you would see a demo in which you can describe a scientific idea, and ”AI” would spit out relevant articles. Or if you ask a question, the model would answer. Some cherry-picked examples can now be seen here https://galactica.org/explore. The demo was out there for 3 days, and then Twitter simply smashed it, and the demo was closed.
A version in Russian is found below.
Here is one of the threads, the gist is that the model palms off non-existent articles, makes factual mistakes (just like, generally, almost any Language Model), introduces its own biases and, in general, authoritatively declares facts that can lead researchers astray. Here is one of the innumerable articles on the topic.
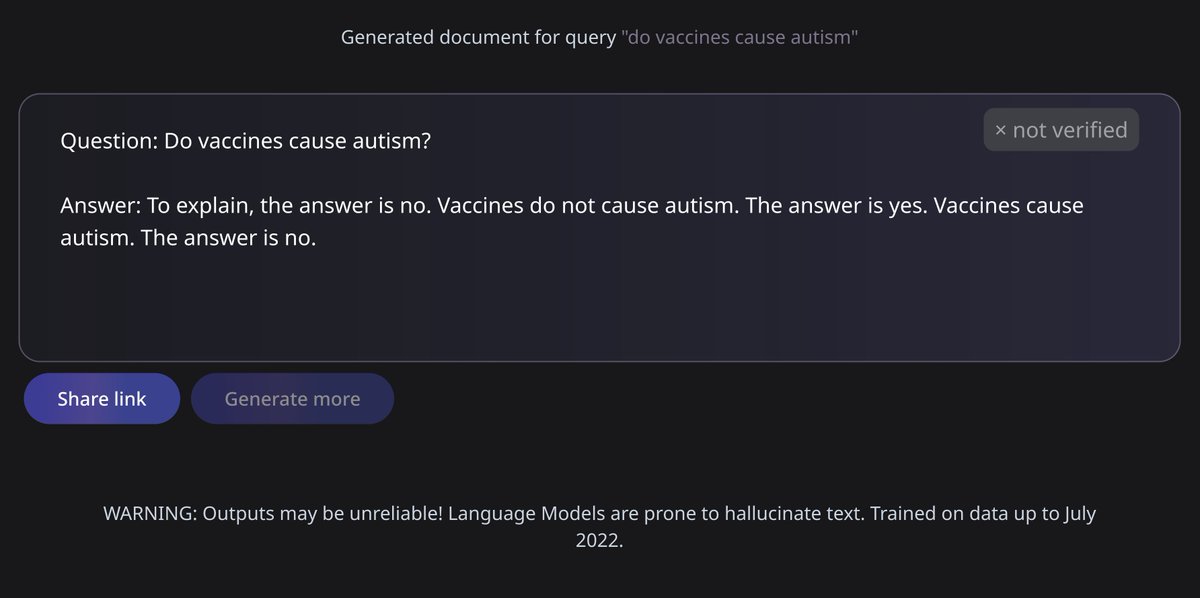
The great AI’s take on the vaccines & autism debate.
I’m not saying that you shouldn’t experiment, of course, you should. It’s just that any experiment is aimed at testing some hypothesis, and in this case, the hypothesis was false from the very beginning. Language models cannot yet be a reliable source of verified scientific knowledge. It is rather strange to spend time and resources, run a demo, and expect it to miraculously work out of the box (well, Meta researchers could’ve at least integrated the LM with databases and/or knowledge graphs to avoid factual mistakes). And in general, the truth is that all sorts of natural language understanding techniques are not about understanding at all. We have no understanding of what neural networks actually “understand”. We tend to build transformers on top of transformers, mixed with transformers, play around with embeddings, change config files, learning rates, explore model errors, etc. and then we try to find some patterns in the NN’s behavior. Until we proudly (or humbly) claim that we understand something about our NN “understanding” something. Not surprisingly, interpretability, causal inference, reliable ML, and adjacent areas are among the hottest in ML these days.
My favorite example of how what seems possible turns out to be useless in practice (a pretty typical story for Data Science in general, let’s admit) is how the Open Data Science community tried to make a recommender system for commonly asked questions. In an actively growing community, newcomers came in and asked a lot of duplicate questions. It seems that there is a lot of data, you can train an ML model, and create a bot that would annoy you with hints like “you asked about transformers, but here’s another similar question about Bert”. The result is predictable: the recommendations were more like the notorious “oh, you tried chocolate, you probably enjoy brown, try 💩”, and the community members reacted to the bot’s suggestions accordingly, until it was turned off in the end. A bitter irony… there is a community of IT specialists, data scientists, and machine learning scientists, and the community failed to solve its own pain point in a seemingly mundane recommender project.
And finally, bullshit. It seems that managers of at least large companies are beginning to understand that some tasks can be solved really well, and some seemingly similar ones cannot be solved at all or can only be solved at a too high cost. However, it is still common to hear suggestions like “let AI find sound science” (whether a scientific article is reasonable or non-sensical) or “let’s create layman summaries of scientific articles for the general public” (a bit of provoking here: but in my view, summarization is just not there yet).
So, be critical, when you hear “AI”, try to replace it with “matrix multiplier” (or Advanced If-else, if you wish) and develop your own internal AI-bullshit detector, as well as some model that’d distinguish possible and impossible. If you develop a good prior of what is possible and what is not, you can save a lot of time by discarding bullshit right at the brainstorming stage.
A version of this post in Russian
The corresponding Telegram post.
Понять, что возможно, а что невозможно – одна из главных задач, ежедневно решаемых наукой. В области машинного обучения это особенно заметно. Возьмем недавнюю Галактику от Meta AI – большую языковую модель, обученную на научных статьях. Еще недавно, зайдя на https://galactica.org, вы бы увидели демку, в которой описываешь научную идею, а Эй-Яй выдает тебе релевантные статьи. Или задаешь вопрос, а модель отвечает. Сейчас черри-пикнутые примеры можно увидеть тут. Провисела демка дня 3, да и разнес ее Твиттер в пух и прах – демку закрыли. Вот один из тредов , суть в том, что модель подсовывает несуществующие статьи, ошибается в фактической информации (как и все LM), вносит свои биасы и вообще “уверенным тоном” авторитетно заявляет факты, которые могут сбивать исследователей с пути истинного.
Я не говорю, что не надо экспериментировать, конечно надо. Просто любой эксперимент направлен на проверку гипотезы, а в данном случае гипотеза была ложной с самого начала. Языковые модели пока не могут быть надежным источником верифицированных научных знаний. Довольно странно потратить время, ресурсы, запустить демку и ожидать, что оно чудом заработает как надо. И вообще правда в том, что всякие техники natural language understanding – они вовсе не про понимание. У нас нет понимания, что нейронки “понимают”. Мы городим какие-то хурмомятни из трансформеров, крутим эмбеддинги, меняем конфиги, темпы обучения, смотрим на ошибки модели и чаще всего пытаемся нащупать какие-то паттерны поведения нейронки, такие что можно будет сказать, что мы что-то что-то понимаем и нейронка что-то понимает. Так что недаром сейчас interpretability и смежные области активно развиваются.
Мой любимый пример того, как кажущееся возможным оказывается на практике бесполезным (очень характерно в целом для Data Science) – как в сообществе ОДС пытались сделать систему рекомендации похожих вопросов. Суть в том, что когда сообщество активно росло, новички приходили и задавали много однотипных вопросов. Вроде и данных много, можно обучить модельку и дальше бот будет совать подсказки типа “вы спросили про трансформеры, а вот еще вопрос про берта”. Итог предсказуем: рекомендации были больше похожи на пресловутое “вы пробовали шоколад, наверное вам нравится коричневое, попробуйте 💩”, и члены сообщества соответствующими эмоджи как раз и забросали бота – его выключили в итоге. Какая-то горькая ирония… не то чтобы сапожник без сапог, но вот есть сообщество айтишников-датасаентистов-машинлернеров, и оно само себе не смогло помочь с вроде бы типичной задачей.
И наконец, булщит. Кажется, что менеджеры хотя бы крупных компаний начинают понимать, что некоторые задачи решаются неплохо, а некоторые, вроде бы и похожие, но могут вообще не решаться или решаться дорого. Тем не менее, все еще довольно часто можно слышать предложения типа “давайте AI будет предсказывать sound science” (разумна ли научная статья или там бред написан) или “давайте писать пересказы научных статей для широкой публики” (да-да, суммаризация пока вообще не работает).
Морали нет. Разве что будьте критичны, заменяйте в мыслях “AI” на “перемножатель матриц” (или Advanced If-else, если угодно) и развивайте свой собственный внутренний AI-булщит детектор, а также классификатор возможного и невозможного. Если иметь хороший prior относительно того, что возможно, а что нет, можно неплохо времени сэкономить, отметая ненужное еще на этапе брейнсторминга.