Here I’m trying to discover ChatGPT’s weaknesses and test its ability to resolve coreferences in natural text and crack mlcourse.ai assignments. Naturally, I could not resist playing with the new OpanAI chatbot chatGPT with the goal of spotting some of its weaknesses. Quite a few have already been pointed out, e.g. Sergey Ivanov even measured chatGPT’s IQ.
A version in Russian is found below.

ChatGPT’s IQ test. Source.
chatGPT and a Kaggle pronoun resolution task
I decided to test the chatbot in the coreference resolution task. This was the first Kaggle competition where people started using BERT-like models. I clearly remember how we fiddled with all sorts of old school models until Matei Iinota (a would-be first author of our research paper based on the competition) smashed the leaderboard by posting a BERT-based solution (no HuggingFace back then, the solution was based on Google’s BERT source code in TensorFlow).

Part of the Gendered Pronoun Resolution competition description. Source.
Let’s explain what the task is about. A simple example of coreference resolution: given two sentences
“Lucy went to the gym. Her dog stayed at home”
try to figure out that the pronoun “her” refers to Lucy.
A similar example, but a bit more complicated example:
“Lucy went to the Maria. Her dog stayed at home”.
Now we need to infer that “her” refers to Lucy, not Maria.
In the competition, the examples were more complicated, where even a human needs to burn some brain fuel to resolve coreference.
Zoe Telford – played the police officer girlfriend of Simon, Maggie. Dumped by Simon in the final episode of series 1, after he slept with Jenny, and is not seen again. Phoebe Thomas played Cheryl Cassidy, Pauline’s friend and also a year 11 pupil in Simon’s class. Dumped her boyfriend following Simon’s advice after he wouldn’t have sex with her but later realised this was due to him catching crabs off her friend Pauline.”
Try to read this passage and infer who the bolded pronoun “her” refers to. Not so easy, is it? However, the task is simplified: for each example, they provide two options, in this example: Cheryl Cassidy (option A) or Pauline (option B). A pronoun can also refer to none of A or B. In this case, the answer is Cheryl Cassidy.
In the competition, we needed to perform coreference resolution only for pronouns, and thus the task type was pronoun resolution.
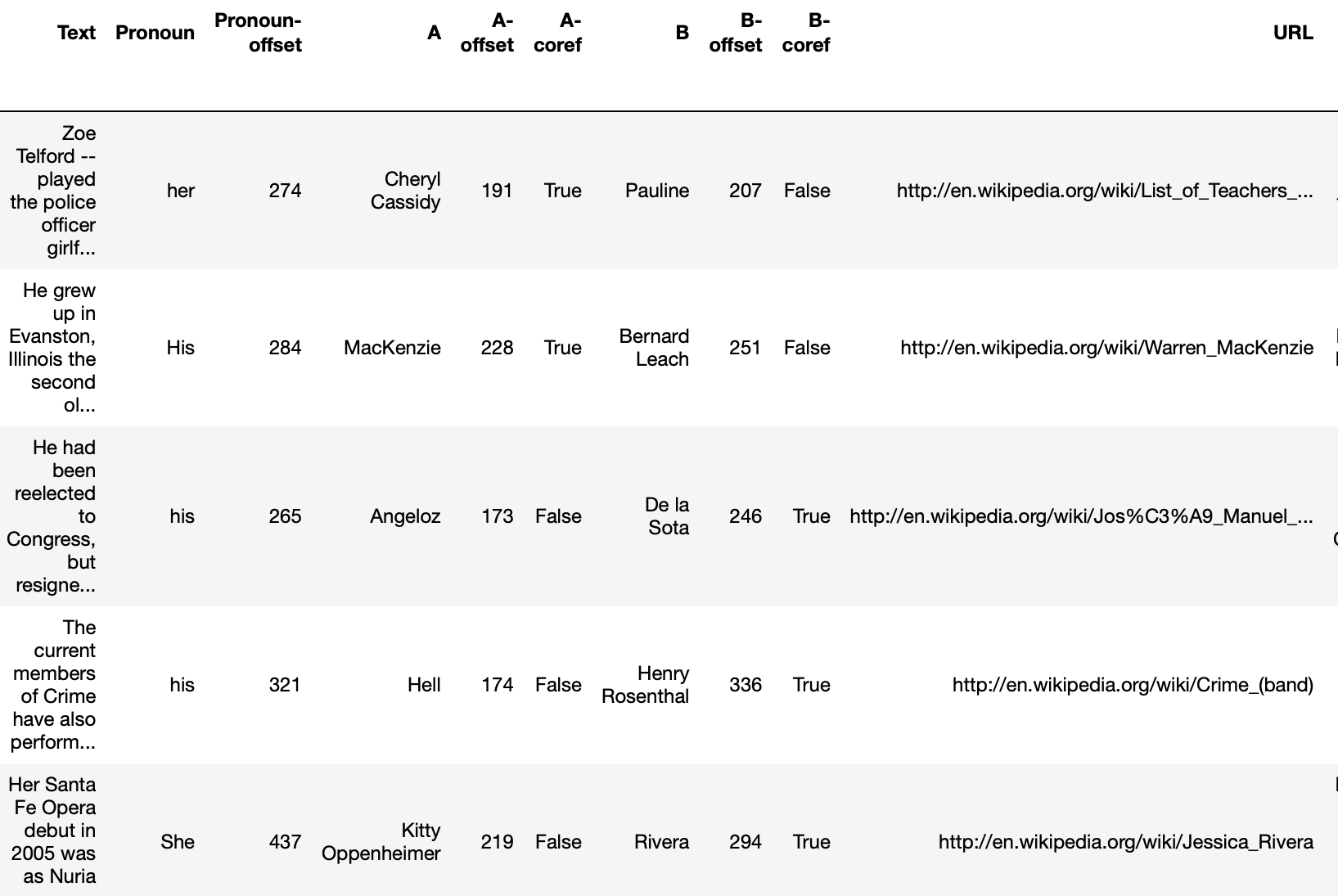
First 5 rows of the GAP development set. A Wikipedia text excerpt is given, with the pronoun Pronoun and its char offset, named entities A and B with their offsets, and binary flags A-coref and B-coref - whether the pronoun refers to A, B, or neither of them.
In such a problem setup, vanilla BERT without fine-tuning hits 76% accuracy. later in the competition, we saw that an ensemble of fine-tuned BERTs pushes this closer to 98%.
I built up some patience and fed 100 examples from this Kaggle problem into chatGPT3 in a format
“{Text}. Does ‘{Pronoun}’ at an offset of {offset} chars refer to {A} or {B}?”.
The result? Far from a fine-tuned BERT, but chatGPT hit 76% accuracy, the same as BERT that was not fine-tuned for the task (and 69% micro F1 score, comparable to un-fine-tuned BERT, just a bit less).
I was pleased to see that chatGPT3 tried to explain why it believes that the pronoun refers to one person, and not to another.

In such a zero-shot problem statement, that’s a fairly good no-code solution. isn’t it? At least when compared to vanilla BERT (which we treat as something given now in 2022) which also required the whole Kaggle community to tinker for a couple of weeks back then in 2018.
It will be interesting to check chatGPT3 with Winograd schemes, simple examples in which the reader (either a human or an algorithm) needs both knowledge and commonsense reasoning to perform anaphora resolution. Example:
“The city councilmen refused the demonstrators a permit because they [feared/advocated] violence”.
Depending on the choice of “feared” or “advocated”, the pronoun “they” refers to either “councilmen” or “demonstrators”.
chatGPT cracking mlcourse.ai assignments
I also found that chatGPT3 scored 7/10 in the 1st mlcourse.ai demo assignment. It generates valid code with comments, although sometimes things can be done much simpler. It struggles though with generalization, e.g. answering “are there more men than women?” once the numbers are there.
For demo assignment 8, chatGPT3 also created a perfect implementation of the Stochastic Gradient Regressor which works, and the model explained how to use it.

Conclusion
I’ll go on fiddling with chatGPT but the intermediate conclusion is quite philosophical. In the past, when I heard “AI”, I’d always stress that we, ML specialists, are dealing with machine learning, and not “artificial intelligence”. “AI for advanced If-Else”, “matrix multiplication” will conquer the world and all sorts of similar jokes. Now I’ll be more humble with such reservations, we can already see how machine learning leads to actual (weak) artificial intelligence. At some point, they’ll model commonsense reasoning, tie together language, voice, photo- and video models, add knowledge graphs, databases, and Internet access plus some technologies that we are not aware of yet - and wow, it’s hard to imagine what the outcome will be. Exciting times!
A version of this post in Russian
The corresponding Telegram post.
Итоги года подводить вроде еще рано, но можно смело сказать, что chatGPT3 – важнейшее, что произошло в 2022 в области машинного обучения.
Конечно, я не мог пройти мимо этого чатбота и не попытаться его в чем-то подловить. Это уже многие сделали, например, Сергей Иванов даже замерил IQ chatGPT3 (результат: 83, ниже среднего). Я потестил чатбота в задаче coreference resolution. К слову, это было первым Kaggle-соревнованием, где люди начали использовать BERT-подобные модели. Я прямо помню, как мы возились со всякими олд-скул моделями, пока парень не разорвал лидерборд, выложив решение на основе берта (тогда еще не было HuggingFace, все на базе исходного гугловского кода).
Простой пример coreference resolution: по двум предложениям “Lucy went to the gym. Her dog stayed at home” понять, что местоимение “her” относится к Lucy. Похожий пример, но посложнее: “Lucy went to the Maria. Her dog stayed at home” - надо понять, что “her” относится к Lucy, а не к Maria. В соревновании примеры были посложнее, там уже и человеку надо сжечь немало глюкозы, чтоб разрешить такие кореференции.
“Zoe Telford – played the police officer girlfriend of Simon, Maggie. Dumped by Simon in the final episode of series 1, after he slept with Jenny, and is not seen again. Phoebe Thomas played Cheryl Cassidy, Pauline’s friend and also a year 11 pupil in Simon’s class. Dumped her boyfriend following Simon’s advice after he wouldn’t have sex with her but later realised this was due to him catching crabs off her friend Pauline.”
Попробуйте прочитать этот отрывок и понять, к кому относится “her”, выделенное жирным шрифтом. Задача упрощается тем, что даются два варианта: “Cheryl Cassidy” или “Pauline” (местоимение может и не относиться ни к одному из них). В данном случае ответ: Cheryl Cassidy.
Вот в такой постановке задачи ванильный BERT без дообучения выбивает 76% accuracy. Потом мы уже увидели, что с дообучением BERT уже и под 98% умеет.
Я набрался терпения и подал chatGPT3 на вход 100 примеров из этой Kaggle-задачи в формате “{Text}. Does ‘{Pronoun}’ at an offset of {offset} chars refer to {A} or {B}?”. И что ж, до файнтюненного берта, конечно, далеко, но получилось как раз 76% accuracy (и 69% micro-F1, что совсем чутка меньше, чем у недообученного берта). Порадовало, что chatGPT3 пыталась объяснить, почему считает, что местоимение относится именно к одному человеку, а не к другому.
Для такой zero-shot постановки задачи да в no-code стиле это очень даже годное решение на выходе, сравнимое с недообученным BERT-ом, который сейчас считается чем-то данным, а тогда в 2018 всему сообществу Kaggle пришлось изрядно повозиться, чтоб успешно запустить берта.
Интересно будет проверить chatGPT3 в Winograd-схемах, простых примерах, в которых, согласно их создателю, алгоритму нужно проявить здравый смысл (commonsense reasoning). Пример: “The city councilmen refused the demonstrators a permit because they [feared/advocated] violence” В зависимости от подстановки “feared” или “advocated” местоимение “they” относится к “councilmen” или ”demonstrators”.
Еще chatGPT3 довольно сносно ботает задания млкурса. Сэкономлю место, про это рассказал выше.
Что сказать… раньше, когда я слышал AI, я обязательно поправлял, говорил, что мы, специалисты работаем с машинным обучением, а не с искусственным интеллектом. AI for advanced If-Else, перемножатели матриц, вот это все. Сейчас уже надо быть аккуратней, уже видно, как машинное обучение ведет к реальному искусственному интеллекту. Здравый смысл смоделируют, свяжут вместе языковые, голосовые, фото- и видео-модели, добавят графы знаний, базы данных и доступ к Интернету + какие-то из технологий, о которых мы пока и не подозреваем – и ух, сложно представить, что будет.