Apparently, GPT-3 and other language models are so advanced now that generated content, sometimes non-sensical, is bypassing the peer-review process and is being published by Elsevier, Springer Nature, and other publishers. Is there anything that we can do to protect the sanity of scientific content? In this post, I share my experience creating an academic competition (hosted as a COLING workshop Shared Task) and reflect on the immense complexity of the challenge at hand.
Mathgen and SCIgen
Artificially generated content appearing in published papers is a serious challenge that publishers are facing. Mathgen and SCIgen are well-known tools that allow generating whole papers (mathematical or about Computer Science, accordingly) from scratch. These were involved in notorious stories when such manuscripts got published in prestigious journals. For example, Springer once had to retract 120 papers generated by SCIgen.
 Example of a Mathgen-generated paper.
Example of a Mathgen-generated paper.
Luckily, the problems of Mathgen and SCIgen, particularly, have been solved, with Mathgen and SCIgen detectors openly available. For those interested, the paper “Detection of computer generated papers in scientific literature” by Cyril Labbé et. al. describes the techniques used by these generators (Probabilistic Context-Free Grammars and Markov Chains) and how to build detectors.
Deep Learning advancing content generation
Although nowadays, the Mathgen- and SCIgen-generated content is easy to spot, still, with advances in Deep Learning and language modeling, in particular, it’s getting harder and harder to detect excerpts of text that had been generated with Deep Learning. Those of you who studied Deep Learning with the legendary Andrej Karpathy’s Stanford cs231n can easily recall Andrej’s blog post “The Unreasonable Effectiveness of Recurrent Neural Networks” which provides an overview of RNNs with various applications including fake paper generation. Back then, in 2015, LSTMs trained with LaTeX source code were able to produce almost compiling (!) LaTeX code.
, Stanford. This one is produced with an LSTM.*](/images/20221111-detecting-generated-content/johnson_latex_gen_paper.png) One more hallucinated paper, by Justin Johnson, Stanford. This one is produced with an LSTM.
One more hallucinated paper, by Justin Johnson, Stanford. This one is produced with an LSTM.
It’s important to emphasize several points to illustrate the challenges that such techniques pose to the scientific community:
- Such papers generated with LSTMs or other Deep Learning models are much harder to detect as compared to Mathgen and SCIgen, as the model does not rely on fairly simple generation mechanisms like context-free grammars or Markov chains
- Since 2015, the world has seen huge progress in NLP, and we might suggest that transformers would generate even more realistically looking papers than LSTMs
- Even if a part of a paper is generated, it’s still not good and, if non-sensical, might undermine the authority of the journal that published the paper
The notorious GPT-3 model, as publicly admitted, can already produce content that is almost indistinguishable from the human-generated text. Of course, research is done into the peculiarities of GPT-3 generated content and the ways to carefully examine such content and attribute it to GPT-3 (for example, see the Allen AI’s paper “Is GPT-3 Text Indistinguishable from Human Text? SCARECROW: A Framework for Scrutinizing Machine Text”). But given editors’ and reviewers’ workload, it’s easy to imagine that they won’t dive as deep as to try to spot generated content, and thus, the peer-review process might fail to reject partially- or fully non-sensical papers.
“Tortured phrases”
In April 2021, a series of strange phrases in journal articles piqued the interest of a group of computer scientists. The researchers could not understand why researchers would use the terms “counterfeit consciousness”, “profound brain organization”, and “colossal information” in place of the more widely recognized terms “artificial intelligence”, “deep neural network”, and “big data”.
 from a talk by Guillaume Cabanac at Science Studies Colloquium*](/images/20221111-detecting-generated-content/tortured_phrases_slide.png) Some more examples of Tortured phrases found in computer-science papers. Source: slides from a talk by Guillaume Cabanac at Science Studies Colloquium.
Some more examples of Tortured phrases found in computer-science papers. Source: slides from a talk by Guillaume Cabanac at Science Studies Colloquium.
Here are some more examples.

 Sometimes, no doubt, the paper is fraudulent.
Sometimes, no doubt, the paper is fraudulent.
Guillaume Cabanac, Cyril Labbé, and Alexander Magazinov did an investigation of this phenomenon and found quite a few “tortured phrases” in the published scientific literature. In the paper titled “Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals” they openly call the main publishers to investigate the problem. In particular, they explored Elsevier’s “Microprocessors and Microsystems” which experienced a radical change in the number of articles published per volume, together with a considerable shortage of decision times for these articles. This journal had allegedly been attacked by a “paper mill” - the authors found a prevalence of tortured phrases in 2020 and later issues of the journal, and they also run GPT-2 detector and found that the concentration of articles with high GPT-2 scores is outstanding in Microprocessors and Microsystems.
One possible source of tortured phrases is Spinbot.com – a paraphrasing tool. Although the connection with GPT-2 is not yet explored, might be that Spinbot uses GPT-2 under the hood, and thus tortured phrases go together with GPT-2 generated content.
Cabanac et.al. also released Problematic Paper Screener – a web resource that aggregates Tortured Phrases detector, Mathgen, SCIgen, and some more detectors. They openly call out the scientific community to report such papers on PubPeer and then retract them.
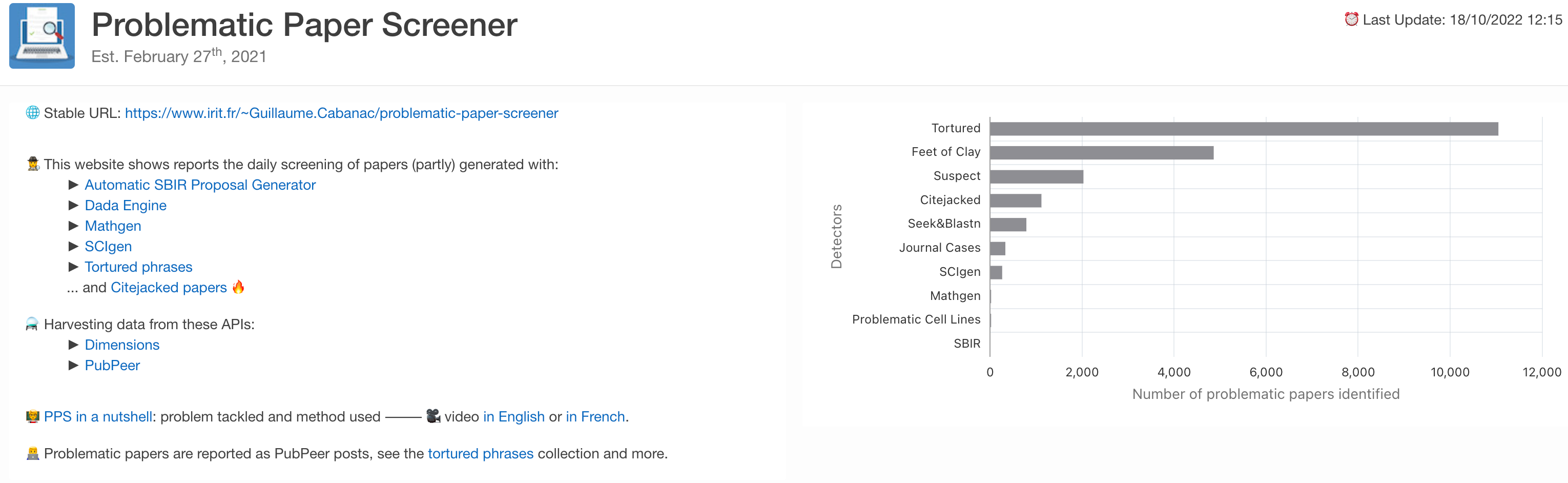 Problematic Papers Screener and Tortured Phrases.
Problematic Papers Screener and Tortured Phrases.
At the time of writing, the Problematic Papers Screener shows 1618 papers containing potential tortured phrases and published by Elsevier. This doesn’t necessarily mean that all of them are nonsensical but some of them certainly are, and the investigation by research integrity experts is in progress.
My own exploration of Tortured phrases
Manual annotation
We collaborated with Cabanac et. al and explored some of the papers published by Elsevier that contained potential tortured phrases. Anita de Waard, Catriona Fennell, Georgios Tsatsaronis, and Yury Kashnitsky, together with the authors of the “tortured phrases” paper, performed an evaluation of 50 papers including suspicious phrases and flagged the majority of them as suspicious. In some cases, published papers indeed made no sense at all.
We are still looking into the ways we can approach “tortured phrases” and flag them to editors, at the moment, though, the “scale of the problem” is not as large as to take immediate action, e.g. build a tool and integrate it into submission systems. Most of the tortured phrases listed by Problematic Papers Screener are seen just dozens of times in papers published by Elsevier.
Tortured phrases and plagiarism
Catriona Fennell, Director of journal services at Elsevier, and team also investigated plagiarism found in retracted papers published by “Microprocessors and Microsystems” and found traces of plagiarism in most of them. Thus, in the case of “Microprocessors and Microsystems”, tortured phrases, GPT-2, and plagiarism all go together. There is still much to explore.
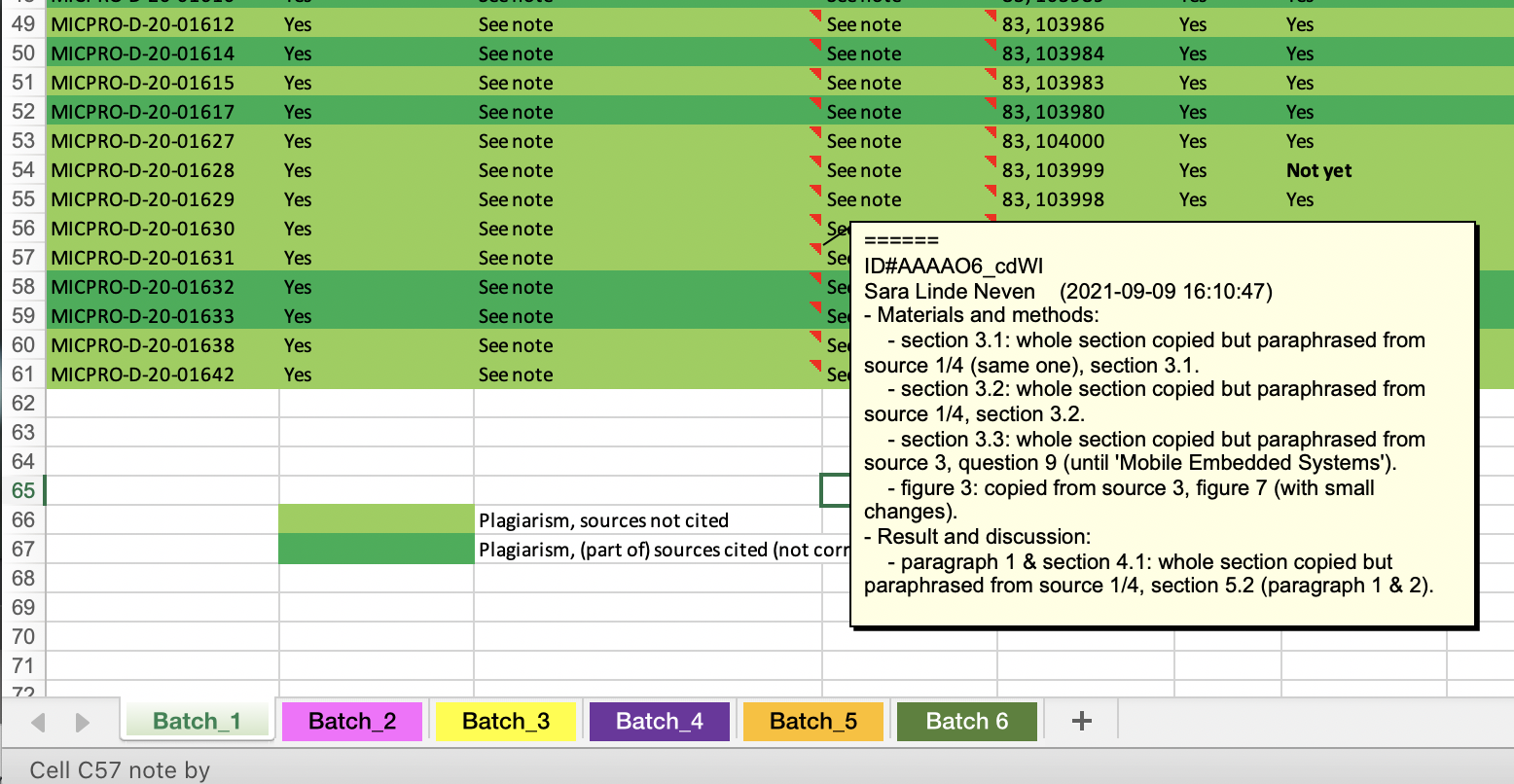 Plagiarism traced in MICPRO papers.
Plagiarism traced in MICPRO papers.
COLING competition
Given this use case with “Microprocessors and Microsystems”, we decided to explore whether generated scientific content, in general, can be detected with help of Machine Learning.
As part of the shared task hosted within the third workshop on Scholarly Document Processing (SDP 2022), held in association with the prestigious International Conference on Computational Linguistics (COLING 2022), we hosted a competition where the task was to classify text excerpts into “fake” and human-generated.
 Kaggle competition page.
Kaggle competition page.
To form training and validation data for the competition, with Dasha’s help, I took excerpts from the retracted “Microprocessors and Microsystems” papers discussed above and some more content that is most probably human-written. Then I used several summarization, paraphrasing, and generating Deep Learning models to create more “fake” content based on the human-written original abstracts.
Specifically, the data for this competition came from 9 sources:
- MICPRO retracted papers (“fake”). These are excerpts from a set of retracted papers of the “Microprocessors and Microsystems” journal (MICPRO). Some of those are explored in (Cabanac et al., 2021) in the context of “tortured phrases”;
- Good MICPRO papers (“real”). Similar excerpts from earlier issues of the “Microprocessors and Microsystems” journal;
- Abstracts of papers related to UN’s Sustainable Development Goals (“real”). Sustainable Development Goals (SDGs) cover a wide range of topics, from poverty and hunger to climate action and clean energy;
- Summarized SDG abstracts (“fake”). These texts were generated using “pszemraj/led-large-book-summary” model;
- Summarized MICPRO abstracts (“fake”). The same model as above was applied to MICPRO abstracts;
- Generated SDG abstracts (“fake”). These texts were generated using the “EleutherAI/gpt-neo-125M” model with the first sentence of the abstract being prompt;
- Generated MICPRO abstracts (“fake”). The same model as above was applied to MICPRO abstracts;
- SDG abstracts paraphrased with Spinbot (“fake”);
- GPT-3 few-shot generated content with the first sentence of the abstract as a prompt (“fake”).
This resulted in 5300 records in the training set and ~21k records in the test set, with 70% of text excerpts belonging to the class “fake”. The code used to prepare competition data is open-sourced.
As an organizer, I provided a simple baseline: Tf-Idf & logistic regression that hits an 82% F1 score with the public competition test set.
I also explored, how accurately this simple model classifies different data sources (e.g. summarized content as opposed to the original human-generated content), the following table shows validation accuracy split by data provenance type.
 Fake papers validation scores, by data provenance type.
Fake papers validation scores, by data provenance type.
We also experimented with back-translated content, e.g. when the original excerpt is translated to, say, German and then back to English. We found that modern translation systems are so advanced that the back-translated snippets look almost identical to the originals, hence we rejected the idea of including such content as “fake”. Repeated back-translation, especially with under-represented languages (say, En -> Swahili -> Korean -> En) might introduce some artifacts and help the back-translated snippets look “more fake”, but we didn’t conduct such experiments.
We see that summarized content was easily detected, probably due to peculiarities of the “pszemraj/led-large-book-summary” summarization model, e.g. most of the summaries are opened with “This paper is focused on…” or “In this paper, the authors …”. Likewise, SpinBot-generated content is easily detected, probably because SpinBot was found to introduce “tortured phrases” (Cabanac et al., 2021) and those can be spotted even with Tf-Idf. Somewhat surprisingly, the model had no problem with retracted MICPRO content.
The model had the most trouble identifying original human-written content, a possible reason is that with all the generated content due to class imbalance ( 70% of the data is “fake”), it’s easy to get false positives when a normal human-written text is easy to be confused with fake content.
Competition outcome
14 teams participated in the task this year, with a total of 180 submissions. Out of these, 11 teams managed to beat the publicly shared Tf-Idf & logreg baseline, and 5 teams managed to beat the fine-tuned SciBERT baseline which was not publicly shared. Three teams submitted peer-reviewed technical reports, of which two are published as part of the workshop proceedings. Both teams managed to achieve >99% test set F1-score.
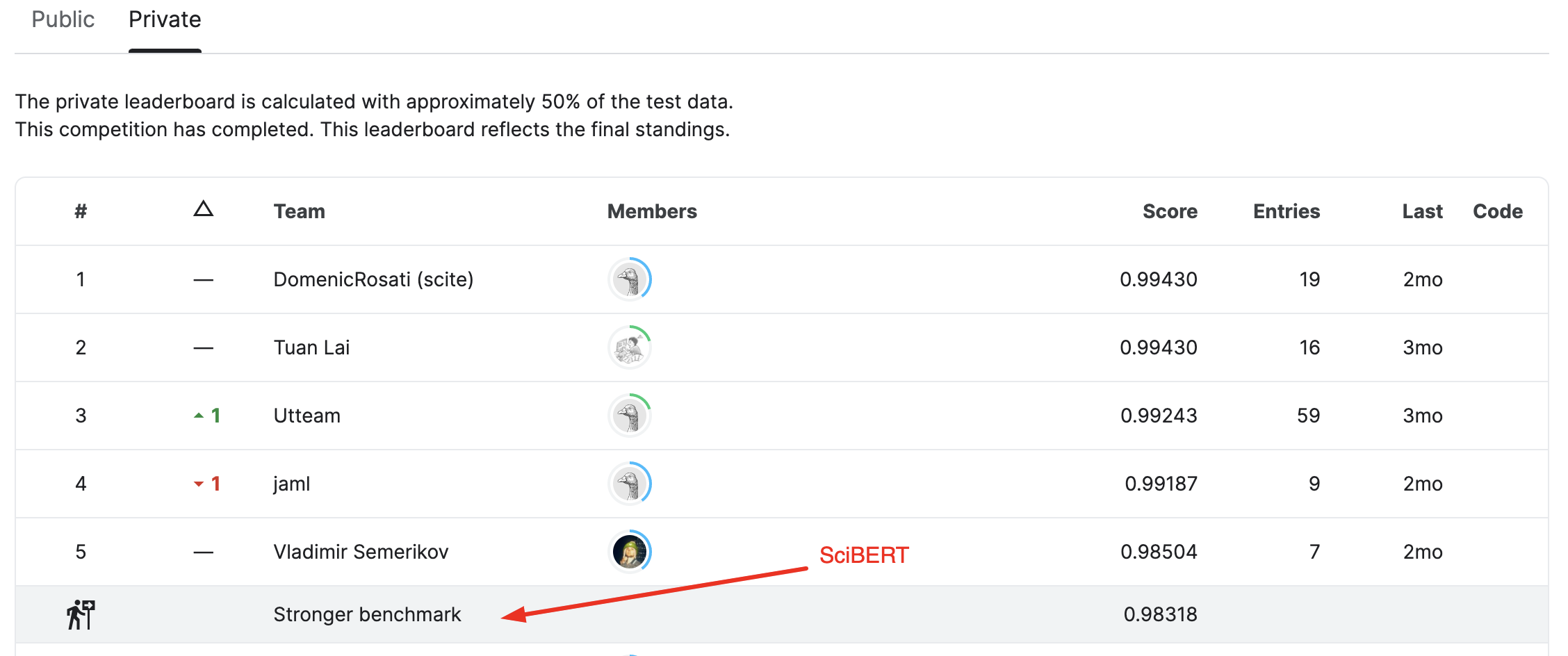 Private leaderboard of the Kaggle competition
Private leaderboard of the Kaggle competition
The winner of the competition Domenic Rosati and the author of the paper “SynSciPass: detecting appropriate uses of scientific text generation” generates a partially synthetic dataset similar to what we as competition organizers had done. Then Rosati shows that the models trained with the competition data generalize badly to a new data source. Ablation studies show that generalization to unseen text generation models might not be possible with current approaches. Rosati concludes that the results in his paper should make it clear that at this point machine-generated text detectors should not be used in production because they do not perform well on distribution shifts and their performance on realistic full-text scientific manuscripts is currently unknown.
Conclusion
It is a bit unfortunate that the competition task turned out to be easy to solve with winners’ models hitting >99% test set F1 scores. It instills the wrong idea that the task of detecting machine-generated content is easy. However, what we observed internally, and what was generously shared by Domenic Rosati in his paper, is that we are far from developing a general detector of generated content, and we need to be humble about such an endeavor. Each new model, say GPT-4, for which we don’t have training data, poses a challenge. And the detector is likely to fail at identifying content generated with such a model, say GPT- 4, due to data shift. We agree that the problem is far from being solved and that at this point we can not rely on detectors of generated content in production systems. The shared task was, however, one step forward in the exploration of this challenging problem.
What’s next
We will be enforcing our efforts on the detection of tortured phrases and generated content in published content as well as submitted manuscripts. There are still ~1600 papers published by Elsevier that are hanging there in the Problematic Papers Screener “Tortured Phrases” dashboard waiting for an investigation. And more ”tortured phrases” can be discovered.
I also agreed with Domenic Rosati (scite.ai) and Cyril Labbé (Université Grenoble Alpes) to organize the next version of a similar competition, to be hosted by COLING 2023 Scholarly Document Processing workshop.
The task is daunting, too challenging to have anything productionized within the coming 2-3 years, but we plan to work on it anyway and make progress.
The team involved
Yury Kashnitsky, Drahomira Herrmannova, Anita de Waard, George Tsatsaronis, and Catriona Fennell.
Cyril Labbé, a researcher at Université Grenoble Alpes, co-author of the paper on tortured phrases.
Links
- Workshop page
- Kaggle competition page
- COLING workshop publications: an overview of the task, and the winner’s paper