Here we cover the best assignments of mlcourse.ai – an open and free Machine Learning course with a good balance of theory and practice. The course is available for free in a self-paced mode, however, the best assignments are shared with Patreon and Boosty supporters.

Citing the legend, “what you cannot create, you do not understand”. Thus, several of the bonus assignments are focused on the implementation of decision trees, random forest, SGD, and gradient boosting from scratch.
Also, we put stress on practice with Kaggle competitions, and in 2 more assignments, you are guided in beating baselines in Kaggle Inclass competitions (“Alice” and “Medium”).
Let’s go through some of the assignments in a bit more detail.
Implementing Decision Trees
Here we’ll go through the math and code behind decision trees applied to the regression problem, some toy examples will help with that. It is good to understand this because the regression tree is the key component of the gradient boosting algorithm which we cover at the end of the course.
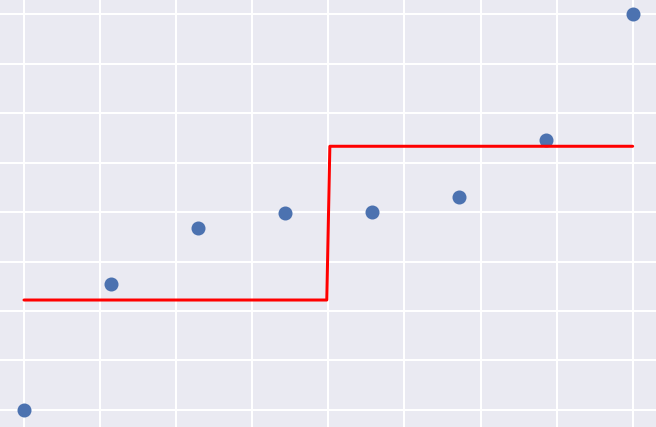
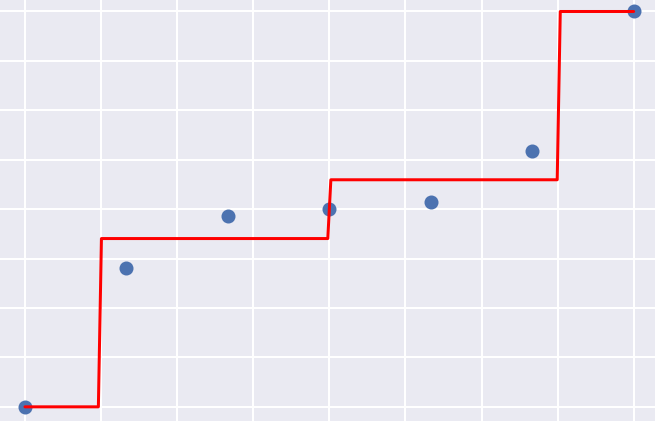
Left: Building a regression tree, step 1. Right: Building a regression tree; step 3
Further, we apply classification decision trees to cardiovascular disease data.
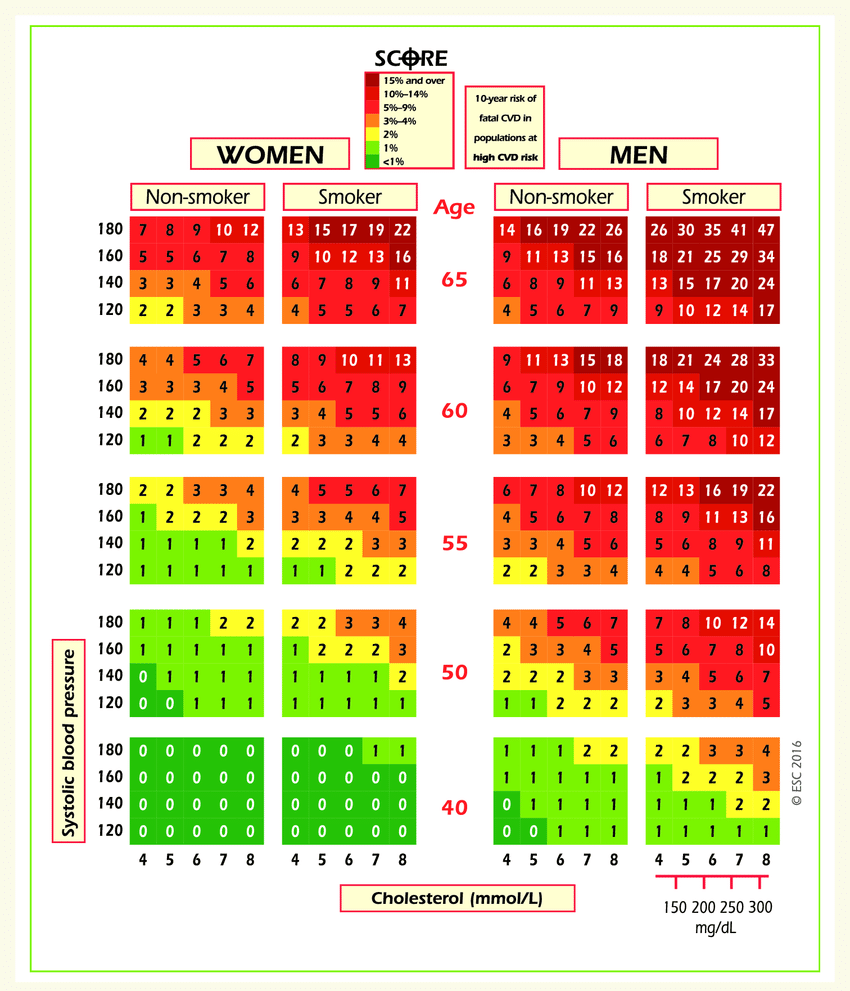
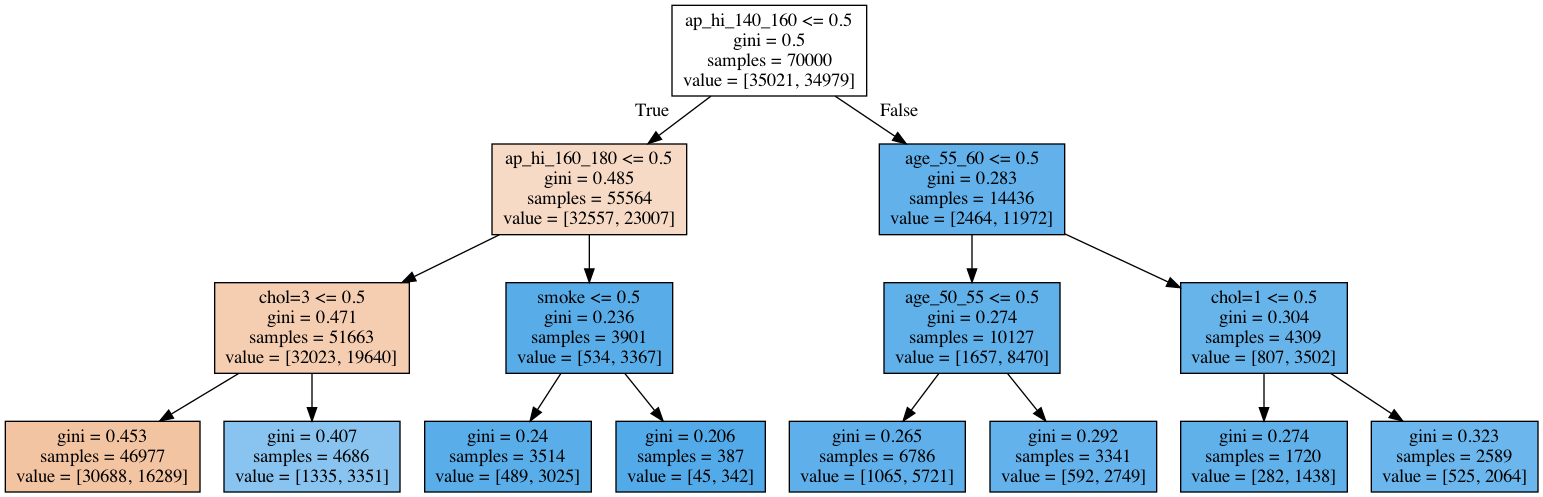
Left: Risk of fatal cardiovascular disease. Right: A decision tree fit to cardiovascular disease data.
In one more bonus assignment, a more challenging one, you’ll be guided through an implementation of a decision tree from scratch. You’ll be given a template for a general DecisionTree class that will work both for classification and regression problems, and then you’ll be testing the implementation with a couple of toy- and actual classification and regression tasks.
Logistic regression vs. Random Forest
In bonus assignment 5, you’ll implement a simplified version of the Random Forest classifier and apply logistic regression and Random Forest in two different tasks – credit scoring and movie reviews classification. This will be great for your understanding of the application scenarios of these two extremely popular algorithms. You’ll also learn the hard way that Random Forest should not be used in case of very large dimensions.
Implementing Stochastic Gradient Descent classifier and regressor
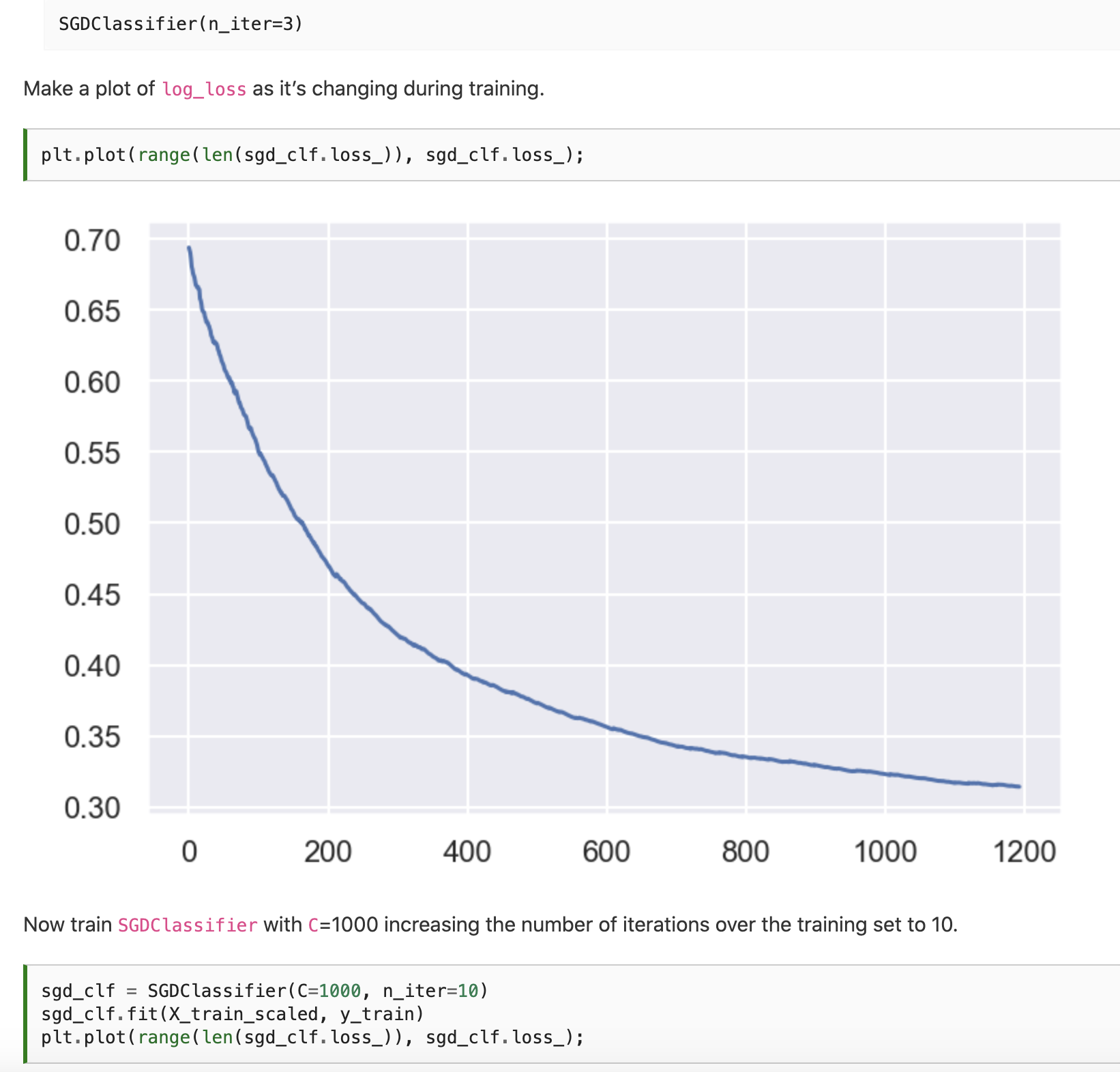
This assignment is an extended version of the demo assignment where the SGD regressor is implemented. Also, we go deeper into the math behind this wonderful optimization algorithm. Here is one of the questions:

Finally, we implement both an SGD regressor and an SGD classifier from scratch and validate both with real-world datasets.

Implementing Gradient boosting
Gradient boosting is one of the most prominent Machine Learning algorithms, it finds a lot of industrial applications. For instance, the Yandex search engine is a big and complex system with gradient boosting (MatrixNet) somewhere deep inside. Many recommender systems are also built on boosting. It is a very versatile approach applicable to classification, regression, and ranking. Therefore, in the course, we cover both the theoretical basics of gradient boosting and specifics of the most widespread implementations – Xgboost, LightGBM, and Catboost.
In this assignment, we go through the math and implement the general gradient boosting algorithm from scratch (by the way, one of the popular ML interview questions is “Where do you find gradients in gradient boosting?”). The same class will implement a binary classifier that minimizes the logistic loss function and two regressors that minimize the mean squared error (MSE) and the root mean squared logarithmic error (RMSLE). This way, we will see that we can optimize arbitrary differentiable functions using gradient boosting and how this technique adapts to different contexts. Here is one of the questions:

Here is one of the visualizations that you build in the process of coding the algorithm and grasping its inner workings.
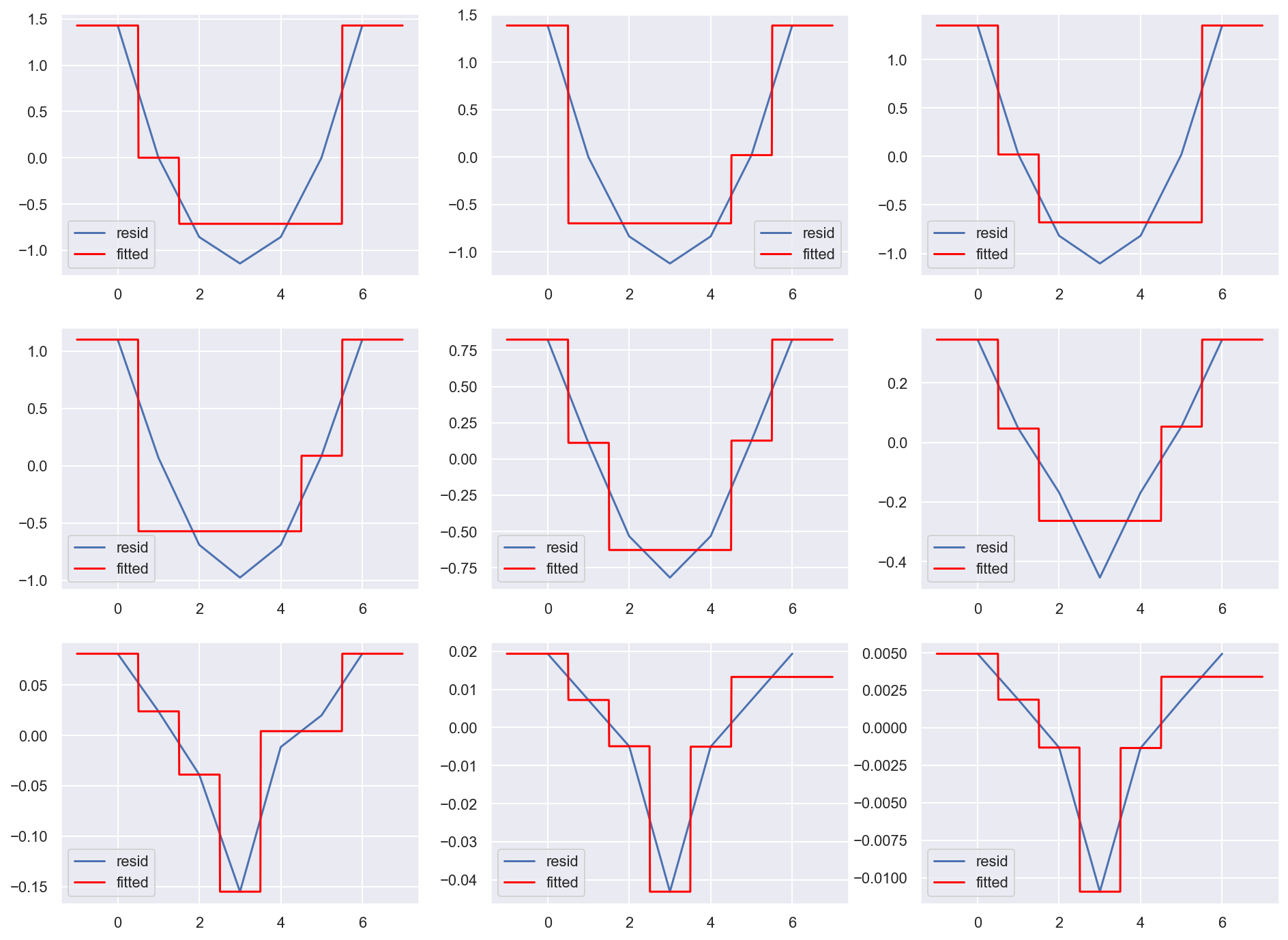
Residuals at each gradient boosting iteration and the corresponding tree prediction.
Beating baselines in the “Alice” competition
In this assignment, you’ll be guided through working with sparse data, feature engineering, model validation, and the process of competing on Kaggle. The task will be to beat baselines in the “Alice” Kaggle competition. That’s a very useful assignment for anyone starting to practice with Machine Learning, regardless of the desire to compete on Kaggle.
The competition is about identifying a user (“Alice”) on the Internet by tracking her web sessions, it’s based on the actual data from one French University. The competition turned out to be very successful, in the sense that the task can be solved well with fairly simple models (literally, logistic regression), and extensive feature engineering.
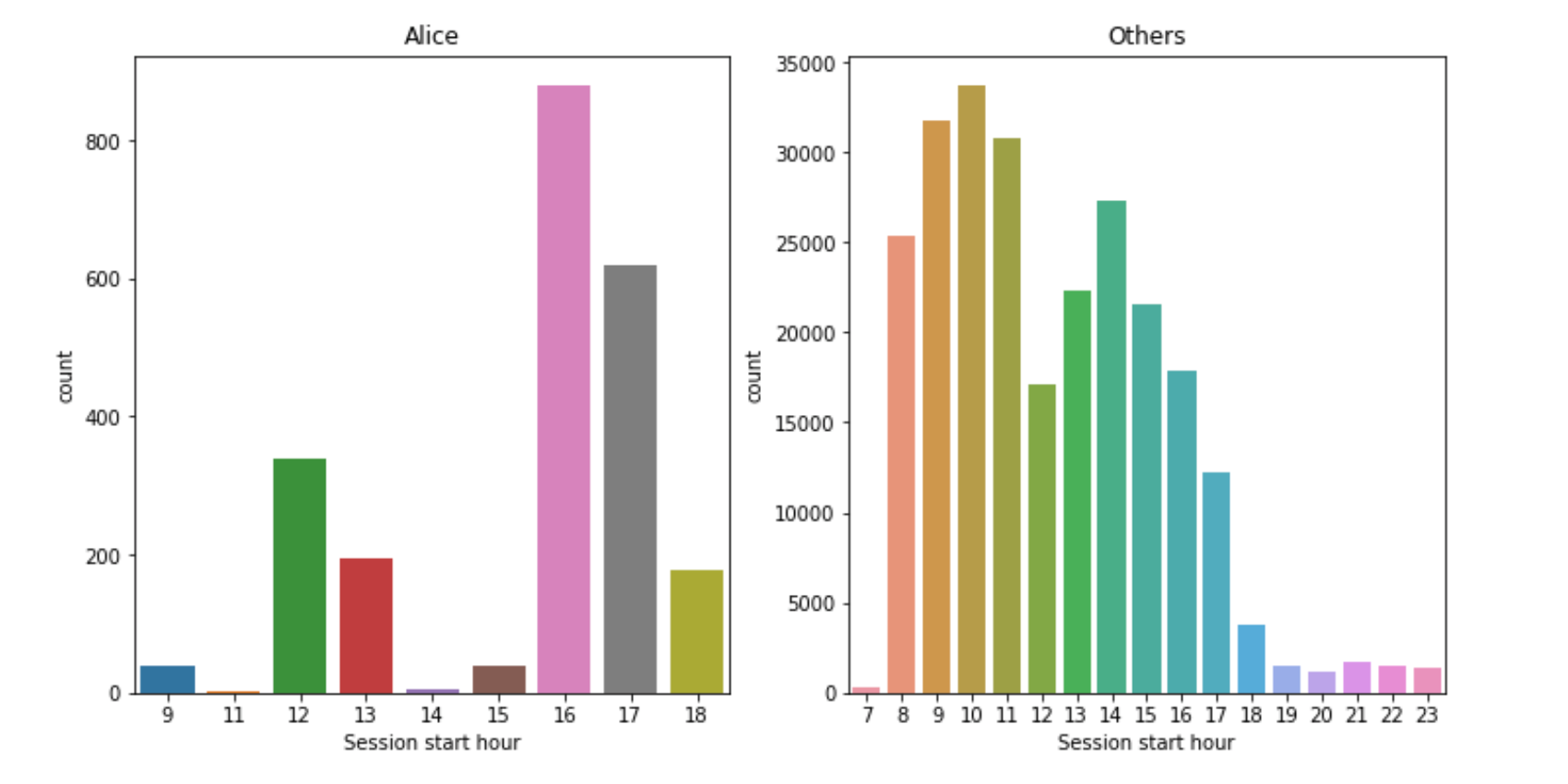
Exploratory Data Analysis and some insights.
For example, the figure above depicts the distribution of session start hours for Alice and others. You might see that distributions are quite different. Hence, such a feature can be added to the model and improve its quality. Such an activity – feature engineering – is a very creative process (we touch it later in the course as well). And it turns out, this competition is very rewarding for thoughtful feature engineering. And well, coming up with good features via visual analysis, adding those to the model, and climbing up the leaderboard – that’s an unforgettable adventure!
In this task, we arm you with a fairly well-performing baseline, and then you are invited to come up with new features and beat baselines.
Beating baselines in the “Medium” competition
In this assignment, you’ll be challenged to beat a baseline in the competition where the goal is to predict the popularity of a Medium article. For this purpose, you’ll be provided with instructions on extracting features from raw JSON files, such as title, author, content, etc. as well as some time-based features.
Here it’s much closer to real-world Data Science, where you spend time fussing with JSONs extracting features, and waiting while the model is being trained. At the same time, just like with the “Alice” competition, feature engineering is the key, and that’s fun.
To purchase a Bonus Assignments pack, select the “Bonus Assignments” tier on Patreon or a similar tier on Boosty (rus).

![]()