mlcourse.ai is an open Machine Learning course by OpenDataScience (ods.ai, led by me. In 2017-2019, I’ve been leading active sessions of the course, offering essential theoretical ground and a ton of practice (assignments, Kaggle Inclass competitions, projects, etc.). All for free. Some 26k people participated, and ~1500 finished the course, I got dozens of direct messages on how passing the course changed the careers of mlcourse.ai alumni. Right now, the course is in a self-paced mode and still has much to offer.
This roadmap guides you through self-paced mlcourse.ai. You can now pass the course as an ODS.ai track as well.
If you prefer a video version, there it is:
First, take a look at course prerequisites. Be ready to spend around 3 months on passing the course, some 4-10 hours/week. Though it heavily depends on how much you will be willing to dive into Kaggle competitions (they are time-consuming but very rewarding in terms of skills) that we offer during this course. To get help, join OpenDataScience, discussions are held in the #mlcourse_ai Slack channel. For a general picture of what role all Machine Learning plays in your would-be Data Science career, check the “Jump into Data Science” video, it walks you through the preparation process for your first DS position once basic ML and Python are covered (slides). In case you are already in DS, this course will be a good ML refresher.
Below we outline the 10 topics covered in the course and give specific instructions on articles to read, lectures to watch, and assignments to crack. You can purchase a Bonus Assignments pack with the best non-demo versions of mlcourse.ai assignments. Select the “Bonus Assignments” tier on Patreon or a similar tier on Boosty (rus).

![]()
Details of the deal
mlcourse.ai is still in self-paced mode but we offer you Bonus Assignments with solutions for a contribution of $17/month. The idea is that you pay for ~1-5 months while studying the course materials, but a single contribution is still fine and opens your access to the bonus pack. Note: the first payment is charged at the moment of joining the Tier Patreon, and the next payment is charged on the 1st day of the next month, thus it's better to purchase the pack in the 1st half of the month. mlcourse.ai is never supposed to go fully monetized (it's created in the wonderful open ODS.ai community and will remain open and free) but it'd help to cover some operational costs, and Yury also put in quite some effort into assembling all the best assignments into one pack. Please note that unlike the rest of the course content, Bonus Assignments are copyrighted. Informally, Yury's fine if you share the pack with 2-3 friends but public sharing of the Bonus Assignments pack is prohibited.Week 1. Exploratory Data Analysis

You definitely want to immediately start with Machine Learning and see math in action. But 70-80% of the time working on a real project is fussing with data, and here Pandas is very good, I use it in my work almost every day. This article describes the basic Pandas methods for preliminary data analysis. Then we analyze the data set on the churn of telecom customers and try to predict the churn without any training, simply relying on common sense. By no means should you underestimate such an approach.
- Read the article (same in a form of a Kaggle Notebook)
- (opt.) watch a video lecture
- Complete demo assignment 1 where you’ll be exploring demographic data (UCI “Adult”), and (opt.) check out the solution
- Bonus Assignment: here you’ll be analyzing the history of the Olympic Games with Pandas. Check the detailed description of the assignment on the course page.
Week 2. Visual Data Analysis
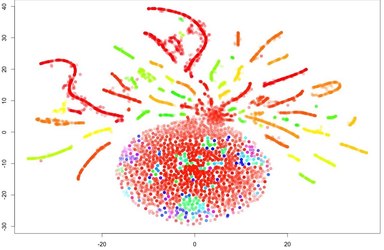
The role of visual data analysis is hard to overestimate, this is how new insights are found in data and how features are engineered. Here we discuss main data visualization techniques and how they are applied in practice. Also take a sneak peek into multidimensional feature space using the t-SNE algorithm, which sometimes is useful but mostly just draws such Christmas tree decorations.
- Read two articles:
- “Visual data analysis in Python” (same as a Kaggle Notebook)
- “Overview of Seaborn, Matplotlib and Plotly libraries” (same as a Kaggle Notebook)
- (opt.) watch a video lecture
- Complete demo assignment 2 where you’ll be analyzing cardiovascular disease data, and (opt.) check out the solution
- Bonus Assignment: here you’ll be performing EDA of a much larger dataset of US flights sometimes attending to the performance of basic operations. Check the detailed description of the assignment on the course page.
Week 3. Classification, Decision Trees, and k Nearest Neighbors
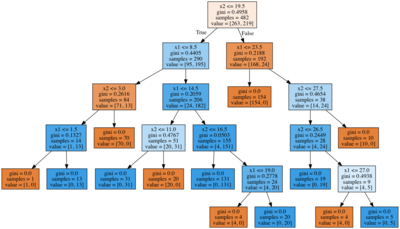
Here we delve into machine learning and discuss two simple approaches to solving the classification problem. In a real project, you’d better start with something simple, and often you’d try out decision trees or nearest neighbors (as well as linear models, the next topic) right after even simpler heuristics. We discuss the pros and cons of trees and nearest neighbors. Also, we touch upon the important topic of assessing the quality of model predictions and performing cross-validation. The article is long, but decision trees, in particular, deserve it – they make a foundation for Random Forest and Gradient Boosting, two algorithms that you’ll be likely using in practice most often.
- Read the article (same as a Kaggle Notebook)
- (opt.) watch a video lecture coming in 2 parts:
- Complete demo assignment 3 on decision trees, and (opt.) check out the solution
- Bonus Assignment: here you’ll be applying decision trees to cardiovascular desease data. In one more bonus assignment, a more challenging one, you’ll be guided through an implementation of a decision tree from scratch. Check the detailed description of the assignment on the course page.
Week 4. Linear Classification and Regression
The following 5 articles may form a small brochure, and that’s for a good reason: linear models are the most widely used family of predictive algorithms. These articles represent our course in miniature: a lot of theory, and a lot of practice. We discuss the theoretical basis of the Ordinary Least Squares method and logistic regression, as well as their merits in terms of practical applications. Also, crucial concepts like regularization and learning curves are introduced. In the practical part, we apply logistic regression to the task of user identification on the Internet, it’s a Kaggle Inclass competition (a.k.a “Alice”, we go on with this competition in Week 6).
It’s better to admit that this week’s material would rather take you 2-3 weeks to digest and practice, that’s fine. But for consistency with article numbering, we stick to “Week 4” for this topic.
- Read 5 articles:
- “Ordinary Least Squares” (same as a Kaggle Notebook)
- “Logistic Regression” (same as a Kaggle Notebook)
- “Regularization” (same as a Kaggle Notebook)
- “Pros and Cons of Linear Models” (same as a Kaggle Notebook)
- “Validation and learning curves” (same as a Kaggle Notebook)
- Watch a video lecture on logistic regression coming in 2 parts:
- the theory behind LASSO and Ridge regression models
- practical part, beating baselines in the “Alice” competition
- Watch a video lecture on regression and regularization coming in 2 parts:
- the theory behind linear models, an intuitive explanation
- business case, where we discuss a real regression task – predicting customer Life-Time Value
- Complete demo assignment 4 on sarcasm detection, and (opt.) check out the solution
- Complete demo assignment 6 (sorry for misleading numbering here) on OLS, Lasso and Random Forest in a regression task, and (opt.) check out the solution
- Bonus Assignment: here you’ll be guided through working with sparse data, feature engineering, model validation, and the process of competing on Kaggle. The task will be to beat baselines in that “Alice” Kaggle competition. That’s a very useful assignment for anyone starting to practice with Machine Learning, regardless of the desire to compete on Kaggle. Check the detailed description of the assignment on the course page.
Week 5. Bagging and Random Forest

Yet again, both theory and practice are exciting. We discuss why “wisdom of a crowd” works for machine learning models, and an ensemble of several models works better than each one of the ensemble members. In practice, we try out Random Forest (an ensemble of many decision trees) – a “default algorithm” in many tasks. We discuss in detail the numerous advantages of the Random Forest algorithm and its applications. No silver bullet though: in some cases, linear models still work better and faster.
- Read 3 articles:
- “Bagging” (same as a Kaggle Notebook)
- “Random Forest” (same as a Kaggle Notebook)
- “Feature Importance” (same as a Kaggle Notebook)
- Watch a video lecture coming in 3 parts:
- part 1 on Random Forest
- part 2 on classification metrics
- business case, where we discuss a real classification task – predicting customer payment
- Complete demo assignment 5 where you compare logistic regression and Random Forest in the credit scoring problem, and (opt.) check out the solution
- Bonus Assignment: here you’ll be applying logistic regression and Random Forest in two different tasks, which will be great for your understanding of the application scenarios of these two extremely popular algorithms. Check the detailed description of the assignment on the course page.
Week 6. Feature Engineering and Feature Selection
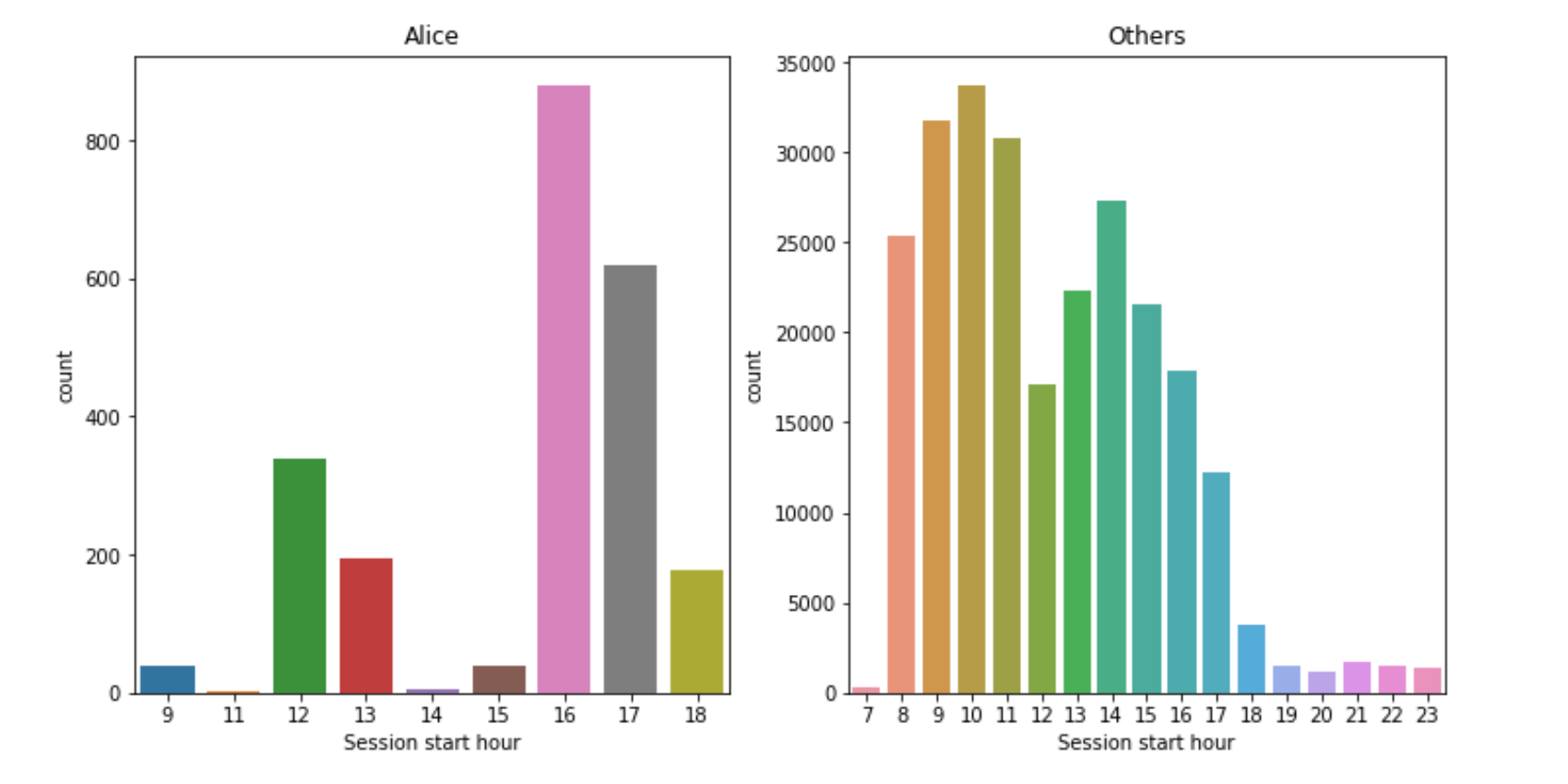
Feature engineering is one of the most interesting processes in the whole of ML. It’s an art or at least a craft and is therefore not yet well-automated. The article describes the ways of working with heterogeneous features in various ML tasks with texts, images, geodata, etc. Practice with the “Alice” competition is going to convince you how powerful feature engineering can be. And that it’s a lot of fun as well!
- Read the article (same in a form of a Kaggle Notebook)
- Kaggle: Now that you’ve beaten simple baselines in the “Alice” competition (see Topic 4), check out a bit more advanced Notebooks:
Go on with feature engineering and try to achieve ~ 0.955 (or higher) ROC AUC on the Public Leaderboard. Alternatively, if a better solution is already shared by the time you join the competition, try to improve the best publicly shared solution by at least 0.5%. However, please do not share high-performing solutions, it ruins the competitive spirit of the competition, and also hurts some other courses which also have this competition in their syllabus.
- Bonus Assignment: here you’ll be challenged to beat a baseline in the competition where the goal is to predict the popularity of a Medium article. For this purpose, you’ll be provided with instructions on extracting features from raw JSON files, such as title, author, content, etc. as well as some time-based features. Check the detailed description of the assignment on the course page.
Week 7. Unsupervised Learning: Principal Component Analysis and Clustering
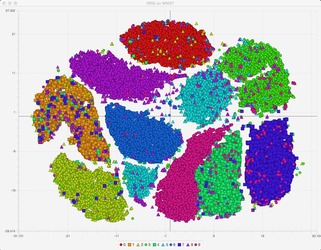
Here we turn to the vast topic of unsupervised learning, it’s about the cases when we have data but it is unlabeled, no target feature to predict like in classification/regression tasks. Most of the data out there is unlabeled, and we need to be able to make use of it. We discuss only 2 types of unsupervised learning tasks – clustering and dimensionality reduction.
- Read the article (same in a form of a Kaggle Notebook)
- (opt.) watch a video lecture coming in 2 parts:
- Complete demo assignment 7 where you analyze data coming from mobile phone accelerometers and gyroscopes to cluster people into different types of physical activities, and (opt.) check out the solution
- Bonus Assignment: here we walk you through Sklearn built-in implementations of dimensionality reduction and clustering methods and apply these techniques to the popular “faces” dataset. Check the detailed description of the assignment on the course page.
Week 8. Vowpal Wabbit: Learning with Gigabytes of Data

The theoretical part here covert the analysis of Stochastic Gradient Descent, it was this optimization method that made it possible to successfully train both neural networks and linear models on really large training sets. Here we also discuss what can be done in cases of millions of features in a supervised learning task (“hashing trick”) and move on to Vowpal Wabbit, a utility that allows you to train a model with gigabytes of data in a matter of minutes, and sometimes of acceptable quality. We consider several cases including StackOverflow questions tagging with a training set of several gigabytes.
- Read the article (same in a form of a Kaggle Notebook)
- (opt.) watch a video lecture coming in 2 parts:
- Complete demo assignment 8 “Implementing online regressor” which walks you through implementation from scratch, very good for the intuitive understanding of the algorithm. Optionally, check out the solution
- Bonus Assignment: This assignment is an extended version of the demo assignment where the SGD regressor is implemented. Also, we go deeper into the math behind this wonderful optimization algorithm. Check the detailed description of the assignment on the course page.
Week 9. Time Series Analysis with Python
Here we discuss various approaches to work with time series: what data preparation is necessary, how to get short-term and long-term predictions. We walk through various types of time series models, from simple moving average to gradient boosting. We also take a look at the ways to search for anomalies in time series and discuss the pros and cons of these methods.
- Read the following two articles:
- “Time series analysis in Python” (same in a form of a Kaggle Notebook)
- “Predicting future with Facebook Prophet” (same in a form of a Kaggle Notebook)
- (opt.) watch a video lecture
- Complete demo assignment 9 where you’ll get your hands dirty with ARIMA and Prophet, and (opt.) check out the solution
- Bonus Assignment: here we are attacking a times series prediction task with a method that has proven to be working well in practice providing quality comparable to ARIMA models. Namely, feature engineering, feature selection and linear models. Check the detailed description of the assignment on the course page.
Week 10. Gradient Boosting

Gradient boosting is one of the most prominent Machine Learning algorithms, it founds a lot of industrial applications. For instance, the Yandex search engine is a big and complex system with gradient boosting (MatrixNet) somewhere deep inside. Many recommender systems are also built on boosting. It is a very versatile approach applicable to classification, regression, and ranking. Therefore, here we cover both the theoretical basics of gradient boosting and specifics of the most wide-spread implementations – Xgboost, LightGBM, and Catboost.
- Read the article (same in a form of a Kaggle Notebook)
- (opt.) watch a video lecture coming in 2 parts:
- Kaggle: Take a look at the “Flight delays” competition and a starter with CatBoost. Start analyzing data and building features to improve your solution. Try to improve the best publicly shared solution by at least 0.5%. But still, please do not share high-performing solutions, it ruins the competitive spirit.
- Bonus Assignment: here we go through the math and implement the general gradient boosting algorithm from scratch. The same class will implement a binary classifier that minimizes the logistic loss function and two regressors that minimize the mean squared error (MSE) and the root mean squared logarithmic error (RMSLE). This way, we will see that we can optimize arbitrary differentiable functions using gradient boosting and how this technique adapts to different contexts. Check the detailed description of the assignment on the course page.