In this post I reason about the claimed accuracy of chatGPT detectors and why the task is far from being solved, in spite of those “99% accuracy” pitches that you hear.
Self-claimed metrics for chatGPT detectors
A colleague pointed me to yet another chatGPT detector with 99% accuracy (on top of GPTZero, DetectGPT, etc.). This Forbes article overviews many of such detectors.
Let’s summarize the claimed self-metrics of the presented detectors:
- TurnitIn: 98% accuracy
- Copyleaks: 99% accuracy
- Winston AI: 99% accuracy
- AI Writing check: 80-90% accuracy
- OpenAI classifier: 26% recall, 91% specificity, with a small math exercise we get 58.5% accuracy
Wait. OpenAI hires the best talents in the whole world. The guys allegedly work for 60-90 hours/week. Is OpenAI really lagging behind the University of Kansas, Winston AI, etc.?
Why is the task hard?
Of course, OpenAI is not lagging behind the University of Kansas and others. The task is actually much harder. While it’s easy to overfit a particular dataset and report 99% scores, it’s much harder to build a generalizable detector that would work for any domain, any language, and any generator (if we allow other models and do not focus solely on chatGPT).
This is a type of task that is hugely susceptible to data drift and model drift (if you’d like the detector to spot content produced by any LLM).
How do I get 99% accuracy and raise money?
Easy. Take a handful of papers, create their chatGPT versions (e.g. with paraphrasing), and train any BERT-type model. Bingo! ~90% scores even in a fair cross-validation setup.
That’s what the University of Kansas did, according to the mentioned Forbes article.
The team of researchers selected 64 perspectives (a type of article) and used them to make 128 articles using ChatGPT, which was then used to train the AI detector. The model had a 100% accuracy rate of identifying human-created articles from AI-generated ones, and a 92% accuracy rate for identifying specific paragraphs within the text.
How detectors failed in the COLING 2022 competition
The argument above is supported by my experience with setting up a COLING 2022 competition track on the detection of AI-generated scientific papers. Here is the full blog post but the gist is the following:
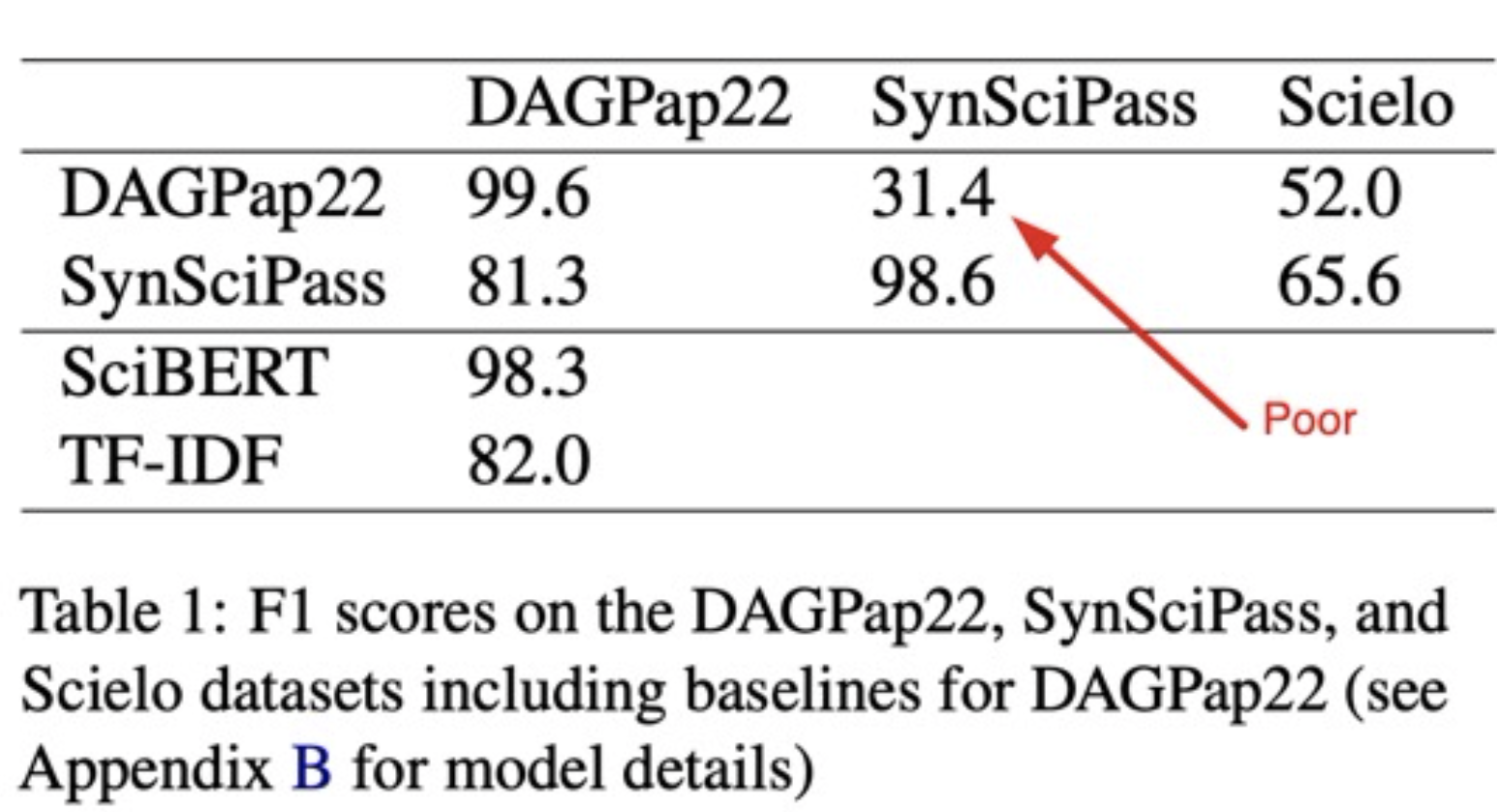
- all the models trained by contestants easily overfitted to the competition dataset, hence 99% F1 scores seen on the leaderboard;
- as one of the winners Domenic Rosati showed with his follow-up paper, the models trained with the provided competition data (
DAGPap22in the table below) generalize very poorly to a new similar dataset that Domenic had generated (SynSciPassin the table below): 31.4% in a binary classification task is worse than random (actually, if we flip the detector’s predictions, that’d yield 1-31.4% = 68.6%).
So where are we with chatGPT text detection?
This needs a whole new post but for now, I’d say: be critical, don’t buy these claims of “99% accuracy” and live with the fact that we’ll probably never know for sure if a piece of text is human-written or completely machine-generated. That’s the new reality.